La aplicación de las evidencias obtenidas en la investigación clínica se enfrenta a diversas dificultades. El paradigma de la investigación basada en la epidemiología clínica, que abarca estudios experimentales y observacionales, está destinado a responder preguntas sobre tratamiento, prevención, diagnóstico o pronóstico. Dicho paradigma es conceptualmente sólido y ampliamente aceptado, pero en la práctica se ve debilitado por diseños inadecuados, escasa orientación al paciente, poca ganancia informativa y falta de contextualización. La abrumadora cantidad de estudios publicados, muchos de ellos irrelevantes o metodológicamente deficientes, dificulta identificar la evidencia verdaderamente útil y supone un desperdicio de recursos1.
En este artículo examinaremos de forma breve cómo el camino entre las conclusiones aportadas por la literatura científica a preguntas pertinentes y la toma de decisiones clínicas se ve condicionado por sesgos de publicación y fallos metodológicos, por artificios interpretativos o por conductas fraudulentas que erosionan su fiabilidad2,3. En un entorno clínico marcado por la incertidumbre, en el que las y los profesionales debemos recurrir a decisiones rápidas, resulta imprescindible adoptar una postura crítica que reconozca estas limitaciones. A partir de esta reflexión, exploraremos ejemplos y estrategias prácticas para detectar debilidades en la evidencia y fortalecer la toma de decisiones en la consulta.
Para ello, agruparemos la problemática de la aplicación de la evidencia en la práctica en tres epígrafes: sesgos y otros errores metodológicos, heurísticos y fraudes.
Sesgos y otros errores metodológicos
Partimos de la definición de sesgo como la combinación de errores que pueden tener lugar durante el diseño, la recogida de datos, el análisis o la difusión de resultados y que tienden a producir resultados que no se deberían haber producido. Estos sesgos pueden haberse cometido de forma más o menos inadvertida, en relación con la potencia del estudio, con errores derivados del uso inapropiado de test estadísticos4,5, cuando los tamaños de efecto son pequeños o cuando la significación estadística se convierte en el resultado que obtener6.
Existen otras deficiencias metodológicas que, aun cuando no impliquen una intención deliberada de distorsión, resultan inaceptables desde una perspectiva científica, como el sesgo de publicación, la falta de discusión de explicaciones alternativas para los hallazgos, selección injustificada de las variables resultado, no pre-registrar los estudios, minimizar u omitir las limitaciones del estudio o exagerar la importancia e impacto de los resultados7. Se explican a continuación las implicaciones de dichos sesgos a través de algunos ejemplos.
Irrelevancia clínica y responsabilidad social
Este error sería de los más importantes a la hora de implantar nuevas tecnologías como nuevos medicamentos, y sucede cuando se atribuye importancia clínica a diferencias estadísticamente significativas sin considerar su relevancia clínica, lo que afectaría a las recomendaciones incorporadas en guías o protocolos, entre otros8,9. Por ello, no solo deben implicarse en su detección los clínicos, sino también todas aquellas agencias públicas y de evaluación de tecnologías encargadas de la financiación de estas a cargo de los presupuestos públicos. Un ejemplo de este tipo de sesgo lo encontramos en la interpretación de los resultados del estudio CAPRIE, cuyos autores concluyeron que el medicamento clopidogrel era más eficaz que el ácido acetilsalicílico para la prevención secundaria de eventos vasculares graves en pacientes con enfermedad cardiovascular previa (infarto reciente, ictus isquémico en los 6 meses anteriores y enfermedad arterial periférica)10. En el grupo de clopidogrel, el riesgo de eventos cardiovasculares fue de 5,32%, comparado con 5,83% en el del ácido acetilsalicílico (p = 0,043), con una reducción del riesgo relativo del 8,7% (intervalo de confianza [IC] 95%: 0,3-16,5) y una reducción absoluta de 0,51% (o 51 eventos por cada 10.000 personas). Esto, en términos clínicos, y teniendo en cuenta la baja tasa de eventos que ocurrió en las dos ramas, parece una diferencia con una relevancia clínica bastante marginal, más teniendo en cuenta que no hubo diferencias en términos de seguridad. Pero los autores no dudaron en presentar una conclusión que de forma taxativa señalaba que el clopidogrel era más eficaz que el ácido acetilsalicílico. Otros resultados que no se presentaron en las conclusiones fueron que no todos los subgrupos de personas con enfermedades cardiovasculares parecían beneficiarse de la misma forma en dicha reducción, sino que, por ejemplo, los que tenían infarto reciente parecía que les fue mejor con el ácido acetilsalicílico, y en los que fueron incluidos con antecedente de ictus no hubo diferencias estadísticamente significativas11. Por último, los organismos que deciden la financiación pública deberían valorar si esa mínima diferencia justificaba el incremento del coste que suponía adoptar la preferencia por el clopidogrel, valorando el coste de oportunidad que puede suponer socialmente.
Mitos y equívocos sobre el tamaño de la muestra
La determinación del tamaño muestral, además de sus implicaciones en la factibilidad del estudio, se encuentra estrechamente vinculada a consideraciones éticas, como la exposición innecesaria de participantes a condiciones experimentales cuando su número supera el requerido para alcanzar conclusiones válidas, así como la posible sobreinterpretación de los resultados obtenidos a partir de tamaños muestrales elevados12. Sin pretender profundizar en aspectos estadísticos, queremos reseñar algunos sesgos que se producen alrededor del tamaño muestral. Cuando calculamos el tamaño de la muestra, realizamos suposiciones sobre medias y desviaciones estándar esperadas o sobre los riesgos de un evento en diferentes grupos (expuestos/no expuestos, rama control/intervención), o bien sobre los tamaños de efecto previstos. Estas suposiciones suelen basarse en estudios previos o en estudios piloto preliminares, a menudo con un tamaño muestral arbitrario. En este contexto, pueden introducirse sesgos al seleccionar dichos estudios, al no considerar de forma adecuada el tipo de diseño (por ejemplo, en estudios multicéntricos o por conglomerados), o al estimar efectos excesivamente optimistas en favor de la propia hipótesis, algo bastante habitual. Otro sesgo frecuente aparece en los estudios con múltiples objetivos. El tamaño muestral suele calcularse en función del resultado principal, por lo que puede resultar sobredimensionado o insuficiente para los resultados secundarios. En consecuencia, estos últimos deberían interpretarse solo como exploratorios, incluso cuando la p sea <0,05, ya que, al contrastar múltiples hipótesis, algunas pueden alcanzar significación estadística por puro azar13. Otro sesgo proviene de la creencia de que un tamaño muestral suficientemente grande ofrece resultados válidos, lo que puede dar lugar a convicciones irreversibles. No es que deba desecharse dicho resultado, pero hemos de estar abiertos a nuevos datos o estudios pequeños que pueden ser válidos y útiles14, y considerar que el tamaño muestral debe tener en cuenta siempre el contexto y los objetivos del estudio8.
Por último, en muestras muy grandes, incluso cercanas al tamaño poblacional, la probabilidad de que no existan diferencias entre grupos es casi nula. En estos casos, un tamaño muestral lo bastante grande hace que incluso diferencias mínimas o asociaciones triviales resulten estadísticamente significativas, sin que ello implique necesariamente relevancia clínica o práctica15.
Generalizaciones inaceptables e indicaciones fuera de ficha técnica (por similitud o difusas)
Este problema surge cuando los resultados de un estudio se aplican a poblaciones o contextos distintos de aquellos para los que fue diseñado y en los que no han sido evaluados. Una manifestación frecuente es la extrapolación indiscriminada de resultados globales a subgrupos sin evidencia específica, como ocurre al prescribir tratamientos en personas mayores cuando los estudios se han realizado en adultos jóvenes, o al indicarlos en mujeres embarazadas sin respaldo empírico. Esto ocurrió con el uso de antidepresivos inhibidores selectivos de la recaptación de serotonina en adolescentes, ilustrado por un ensayo publicado en 2001 que incluyó a 275 adolescentes con depresión y sin antecedentes de conducta suicida, en el que se compararon paroxetina, placebo e imipramina, el fármaco utilizado habitualmente en ese momento, tomando como variable de resultado la mejoría en una escala de depresión16. La compañía que fabricaba la paroxetina había ocultado datos en cuanto a efectos como comportamiento suicida u hostil que fueron más frecuentes en el grupo de la paroxetina y que se habían registrado como labilidad emocional, entre otros datos fraudulentos17-19. Años después, la paroxetina se había prescrito a millones de adolescentes en Estados Unidos y Canadá sin valorar si, además de la depresión, tenían antecedentes de conductas suicidas20.
En cuanto a la ampliación de indicaciones por similitud o confusión, un ejemplo sería el uso de la gabapentina, cuya autorización inicial fue para la epilepsia y el dolor neuropático por herpes zoster21 y que se prescribió por la similitud de síntomas a otras neuralgias, radiculopatías y dolores inespecíficos como el dolor de espalda22,23. Esto volvió a repetirse cuando salió su hermana al mercado, la pregabalina, con uso aprobado para indicaciones particularmente difusas como la fibromialgia, la ansiedad o el dolor neuropático, lo que condujo a que fuese además prescrita de forma habitual para la lumbociática o el dolor de espalda, sin indicación en ficha técnica, y sin estudios de eficacia24,25.
Sesgos en la difusión de resultados
El sesgo de publicación, también conocido como «el iceberg de los estudios negativos»8, hace referencia a la distorsión que se produce cuando los estudios con resultados negativos no se publican, lo que puede alterar la percepción de la eficacia de las intervenciones y conducir a conclusiones erróneas o a prácticas clínicas basadas en evidencia incompleta. Paralelamente, la presión por publicar ha provocado un aumento exponencial en el número de revistas científicas, lo que ha dado lugar a prácticas editoriales cuestionables y criterios de calidad deficientes, como la ausencia de revisiones por pares rigurosas, comprometiendo así la integridad de la investigación publicada. Asimismo, han surgido revistas cuyo objetivo comercial prima sobre el científico. Estas solicitan activamente manuscritos y cobran tarifas de publicación a los autores sin ofrecer procesos sólidos de revisión o edición, motivo por el cual se les ha denominado «depredadoras»26.
Errores en la citación científica y riesgos emergentes con la inteligencia artificial
En las últimas décadas, la gestión de la información médica ha cambiado considerablemente, pero el sistema de referencias en las publicaciones médicas sigue siendo casi el mismo desde principios del siglo XX. Algunas investigaciones indican que hasta un 20% de las referencias bibliográficas son incorrectas, y muchos autores, de forma involuntaria, amplifican los errores de trabajos anteriores al citar fuentes no primarias27. Esto provoca la difusión de afirmaciones y resultados incorrectos, lo que contribuye a la construcción de conocimientos inexactos. A ello se suma el uso acrítico de la información proporcionada por la inteligencia artificial, que en ocasiones incluso puede generar contenidos ficticios o inventar referencias cuando se le solicita. Estos errores subrayan la importancia de una metodología rigurosa y ética en la investigación clínica para garantizar resultados válidos y aplicables.
Heurísticos
En la práctica médica, las decisiones terapéuticas están frecuentemente condicionadas por heurísticos, atajos mentales que agilizan el razonamiento clínico, pero que, cuando se aplican sin la debida reflexión, pueden generar sesgos y errores. Entre los más habituales, se encuentran los heurísticos de anclaje, disponibilidad, confirmación y representatividad, junto con fenómenos como la sobreconfianza, el efecto arrastre, la familiaridad y el afecto. Todos ellos simplifican la toma de decisiones en contextos de presión y tiempo limitado, pero pueden llevar a mantener diagnósticos iniciales, pese a datos contradictorios, priorizar experiencias previas sobre la evidencia, aplicar protocolos sin considerar particularidades del paciente o filtrar la información que respalda la hipótesis inicial28. Reconocer estos mecanismos mentales es esencial para promover un juicio clínico más equilibrado y centrado en el paciente, así como para mejorar la calidad de las decisiones en todos los niveles de gestión clínica.
Vamos a analizar en un ejemplo el camino recorrido de los datos proporcionados por la evidencia clínica a las recomendaciones de una guía de práctica clínica de gran aceptación con el fin de intentar identificar algún «atajo mental» o heurístico.
En las recomendaciones de las guías europeas de 2021 y 2023 sobre el manejo de la insuficiencia cardíaca con fracción de eyección preservada (ICFEp), se observa un cambio notable en el grado de interpretación favorable de la evidencia disponible. La guía de 2021 adoptaba una postura prudente, señalando que ningún tratamiento había demostrado de manera convincente reducir mortalidad o morbilidad en ICFEp y recordaba que ninguno de los grandes ensayos clínicos disponibles había alcanzado sus objetivos primarios29. En contraste, la guía de 2023 introduce una recomendación clara a favor de los inhibidores del cotransportador sodio-glucosa tipo 2 (iSGLT2), en concreto empagliflozina y dapagliflozina, con clase de recomendación I y nivel de evidencia A, lo que implica un elevado consenso y un gran respaldo científico30.
Revisaremos la evidencia que respalda ambas posturas, no para cuestionar la recomendación en sí, sino para comprender cómo se ha ido configurando la valoración de los datos y si existen diferencias en el grado de interpretación clínica positiva o en la forma de analizar resultados que, en algunos casos, son complejos o heterogéneos. Para ello, presentamos brevemente los hallazgos de dos ensayos relevantes: DELIVER, que evalúa dapagliflozina, y TOPCAT, centrado en espironolactona.
El ensayo DELIVER fue un estudio aleatorizado y doble ciego que incluyó 6.263 pacientes con insuficiencia cardíaca y fracción de eyección >40%, comparando dapagliflozina frente a placebo, añadidos al tratamiento estándar. Su objetivo primario fue una variable combinada de empeoramiento de la insuficiencia cardíaca y muerte cardiovascular, evaluada tras una mediana de 2,3 años de seguimiento. El estudio mostró una reducción relativa del riesgo en el objetivo primario (hazard ratio [HR]: 0,82), debida principalmente a una menor tasa de descompensaciones o ingresos por insuficiencia cardíaca. No se encontraron diferencias significativas en mortalidad cardiovascular ni en mortalidad total, de modo que el beneficio observado fue esencialmente la reducción de episodios de empeoramiento clínico (con ingreso)31. A pesar de lo limitado de estos resultados, el estudio señalaba: «Los resultados del ensayo DELIVER pueden orientar futuras guías y proporcionar más evidencia para su uso más amplio en la práctica clínica»31. En 2023, las guías europeas de insuficiencia cardíaca incorporaron la recomendación de usar iSGLT2, basándose en la reducción del criterio combinado observado en EMPEROR-Preserved32, DELIVER31 y un metanálisis33; sin embargo, se precisa que el beneficio se limita a una «menor tasa de hospitalizaciones por insuficiencia cardíaca, sin haberse demostrado reducción significativa de la mortalidad cardiovascular»30.
Compararemos ahora con la recomendación derivada de otros estudios, en concreto los utilizados en la guía de 2021 sobre la espironolactona con el estudio TOPCAT, para ver que quizá haya «atajos mentales» que guían la toma de decisiones.
El ensayo TOPCAT34, aleatorizado y doble ciego, incluyó 3.445 pacientes con ICFEp (fracción de eyección del ventrículo izquierdo [FEVI] ≥45%) tratados con espironolactona o placebo durante una media de 3,3 años. El objetivo primario —muerte cardiovascular, paro cardíaco revertido u hospitalización por insuficiencia cardíaca— no alcanzó significación estadística (HR: 0,89; p = 0,14). Sí se observó una reducción modesta pero estadísticamente significativa en las hospitalizaciones por insuficiencia cardíaca, mientras que no hubo diferencias en mortalidad total ni en hospitalizaciones globales. En conjunto, los resultados individuales son menos distintos de los de DELIVER de lo que podría suponerse, como se muestra en la figura 1.
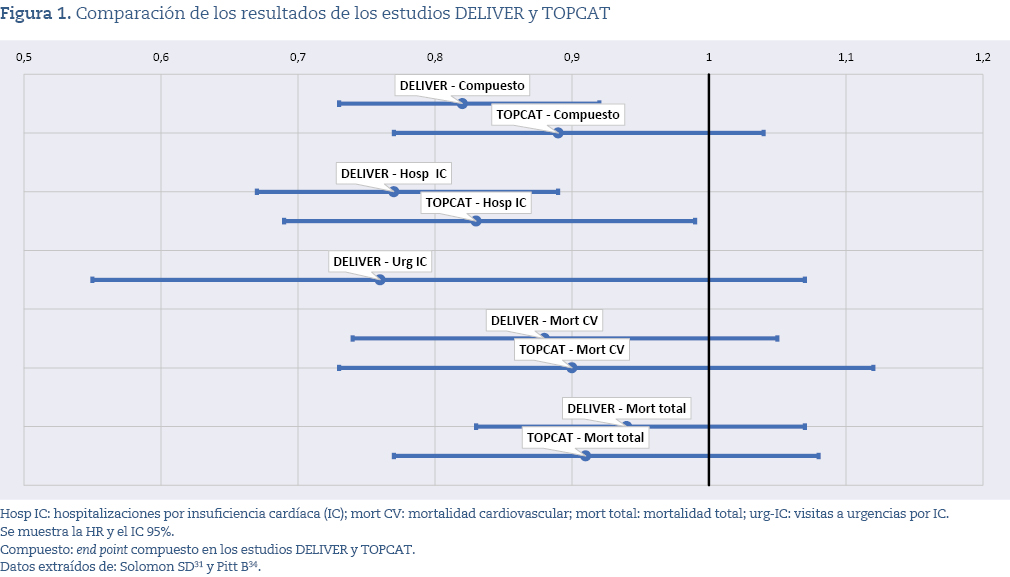
Existen diferencias relevantes entre los estudios DELIVER y TOPCAT que van más allá de los resultados clínicos. El estudio DELIVER, financiado por una empresa farmacéutica, fue seguido rápidamente por un metaanálisis publicado en The Lancet que integró sus resultados con los de otros ensayos, concluyendo que los inhibidores de SGLT2 reducen muerte cardiovascular y hospitalizaciones por insuficiencia cardíaca en un amplio rango de pacientes33. Aunque dicho metanálisis se presentó como preespecificado, su registro en PROSPERO ocurrió tardíamente y con modificaciones posteriores, lo que genera dudas sobre ese extremo35. En contraste, el estudio TOPCAT fue financiado por el National Heart, Lung, and Blood Institute, siguiendo un modelo de investigación financiada de forma pública e independiente de la industria farmacéutica.
Sin querer contradecir las recomendaciones de las guías europeas de 2023, podemos identificar al menos dos tipos de heurísticos en la traslación de los hallazgos a las guías.
Primero, la posible presencia de un heurístico de representatividad, mediante el cual se extrapolan los resultados de un ensayo a todos los pacientes asumiendo que el grupo estudiado es representativo de la población diana. En el DELIVER, aunque se preseleccionaron más de 10.000 pacientes, solo 6.263 fueron incluidos, conformando una muestra muy específica (mayores de 70 años, mayoritariamente caucásicos, predominantemente clase NYHA II, con fracción de eyección media del 54%, alta prevalencia de hipertensión y obesidad, y filtrado glomerular (FG) medio de 61 ml/min/1,73 m2). Los beneficios fueron más claros en ciertos subgrupos, como caucásicos, obesos, hipertensos y pacientes con FG <60 ml/min/1,73 m2 (figura 2). No obstante, las guías clínicas aplican estas conclusiones de forma amplia a todos los pacientes con insuficiencia cardíaca y fracción de eyección preservada, incluso a aquellos con características muy distintas a las de la población incluida.
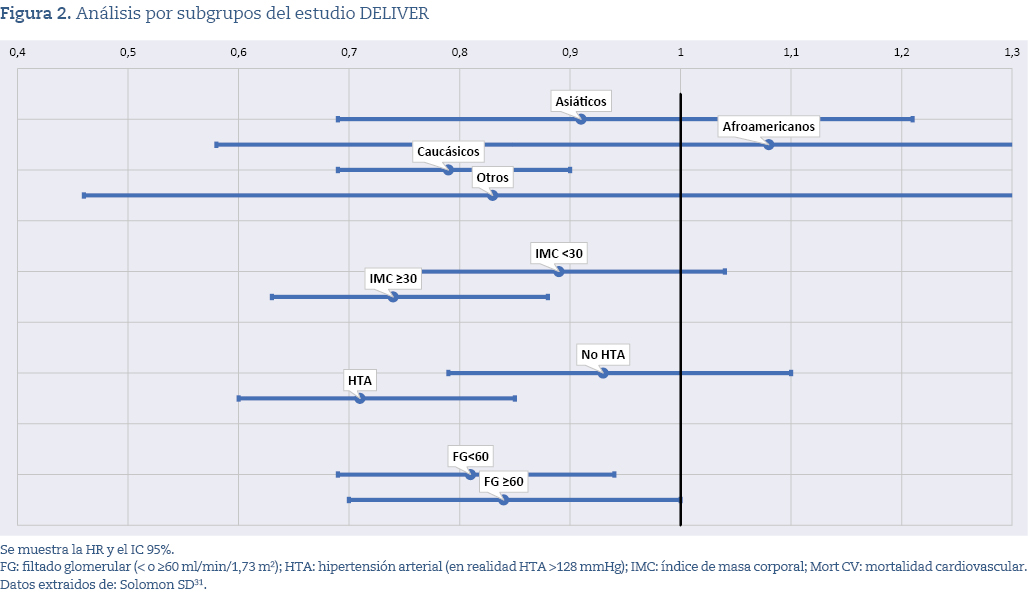
El razonamiento clínico puede verse influido, a su vez, por un heurístico de arrastre, que lleva a adoptar automáticamente las recomendaciones de ensayos influyentes como DELIVER cuando se difunden en revistas prestigiosas y guías internacionales. Esto amplifica el efecto del heurístico de representatividad: primero se extrapolan los resultados de una muestra específica a toda la población y luego la fuerza del consenso y de las guías consolida esa extrapolación, promoviendo que se aplique de forma sistemática sin valorar si los pacientes reales se parecen a los del estudio.
Fraude
El fraude en la investigación clínica constituye una amenaza significativa para la integridad científica y la seguridad de las y los pacientes, ya que puede distorsionar los resultados de los estudios y generar riesgos reales en la práctica médica. A pesar de los controles éticos y metodológicos existentes, los casos de mala conducta continúan apareciendo.
Diversas instituciones han definido el fraude o la mala conducta científica. El US Public Health Service lo describe como fabricación, falsificación o plagio, y excluye los errores honestos o diferencias de interpretación36. El Medical Research Council (MRC) amplía esta definición al incluir la fabricación de datos o documentos, la falsificación mediante manipulación o selección indebida de información, el plagio de ideas o trabajos sin reconocimiento y la tergiversación de datos, resultados, intereses, experiencia o autoría, así como las violaciones del deber de cuidado y el manejo inadecuado de denuncias37.
Por su parte, organismos como el COPE (Committee on Publication Ethics) y el ICMJE (International Committee of Medical Journal Editors) adoptan una visión más amplia que considera la mala conducta como un continuo que va desde el error honesto hasta el fraude deliberado. Además, incluyen en su definición prácticas como la manipulación de imágenes, el ocultamiento de conflictos de intereses o la no publicación de resultados de ensayos clínicos38. En conjunto, estas perspectivas muestran que la mala conducta científica abarca un espectro diverso que excede la definición clásica de fraude.
La magnitud del fraude
La verdadera magnitud del fraude científico es difícil de determinar, ya que quienes lo cometen rara vez lo admiten, los casos detectados representan solo una parte del total y los patrocinadores pueden tener incentivos para ocultarlo. A ello se suman problemas metodológicos, como la falta de consenso sobre qué conductas incluir o qué tipo de estudios evaluar. Las estimaciones varían ampliamente: mientras auditorías formales sitúan el fraude entre 0,01 % y 0,4 %, encuestas a científicos indican que hasta un 20% ha observado o sospecha mala conducta39.
Un indicador indirecto es el número de artículos retractados, aunque este método tiene limitaciones. El crecimiento masivo de la producción científica dificulta el análisis, y algunos estudios muestran que las retractaciones por fraude han aumentado en las últimas décadas. Un análisis de 24,5 millones de publicaciones (1999-2022) observó que las tasas de retractación subieron hasta 2019 y variaban según disciplina, país y tipo de revista; durante la pandemia de la COVID-19, el aumento de publicaciones no se acompañó de mayores tasas de retractación en este campo. Las revistas de menor impacto concentran más retractaciones, lo que sugiere controles más estrictos en las de mayor prestigio40.
Retraction Watch, una web especializada, registra actualmente más de 63.000 artículos retractados41, lo que supone el 0,16% de los 39 millones de referencias de la base Pubmed. Datos recientes muestran un aumento de retractaciones en España, siendo la duplicación el motivo más frecuente, mientras que en biomedicina predominan la fabricación y falsificación de datos42.
¿Cómo detectar el fraude?
Una forma común de detectar el fraude, al menos en un ensayo clínico es la revisión de datos individuales. En los ensayos clínicos aleatorizados, la asignación al azar debe distribuir de forma equilibrada todas las características de los participantes, de modo que cualquier diferencia basal pueda atribuirse al propio azar; cuando aparecen desequilibrios improbables o patrones incompatibles con una distribución aleatoria, se cuestiona la aleatorización y la validez del estudio. Una de las herramientas más utilizadas para detectar estas anomalías es el análisis estadístico propuesto por Carlisle, basado en examinar valores p de variables basales para identificar patrones extremadamente improbables. En 2012, J.B. Carlisle, un anestesista, que fue editor de la revista Anaesthesia, publicó un análisis crítico sobre los ensayos clínicos de un solo autor, realizados entre 1991 y 2011. Carlisle analizó 168 trabajos de dicho investigador, comparando variables con las distribuciones esperadas. Encontró que el 85% de las variables (28 de 33) presentaban inconsistencias con probabilidades extremadamente bajas de ocurrencia por azar. Estos hallazgos presentaban patrones estadísticos muy improbables, lo que sugería la posibilidad de manipulación o fabricación de datos43.
Posteriormente, Carlisle aplicó un análisis similar a miles de ensayos clínicos aleatorizados de múltiples autores, publicados en revistas como Anaesthesia, Journal of Anaesthesia, European Journal of Anaesthesiology, JAMA y New England Journal of Medicine. Utilizó los valores p derivados de las comparaciones de las medias basales de los grupos para detectar anomalías, y encontró un exceso de valores difíciles de explicar por el azar, lo que indicaba patrones improbables que podrían reflejar manipulación o fraude. Estos patrones eran mucho más frecuentes en ensayos retractados que en los no retractados. Aunque algunas anomalías podrían explicarse por errores no intencionales o metodologías deficientes, los patrones fueron consistentes en todas las revistas analizadas. Este enfoque estadístico permite identificar ensayos potencialmente fraudulentos, facilitando su corrección o retractación44.
Además, la revisión de datos individuales, empleada por el propio Carlisle en 2021, multiplicó la capacidad de identificar fraude y reveló que una proporción significativa de ensayos contenía datos falsificados45.
Aunque el método de Carlisle presenta limitaciones, como la ausencia de corrección por comparaciones múltiples, lo que incrementa la probabilidad de falsos positivos46, su enfoque ha sido reconocido por epidemiólogos de referencia, quienes destacan que detectar datos falsos en una parte del ensayo obliga a cuestionar la integridad del conjunto, incluidos procesos clave como la aleatorización, el cegamiento o la recogida de datos. Por ello, instan a financiadores, reguladores y sistemas académicos a promover la apertura y el rigor en la investigación mediante incentivos y sanciones para reducir la circulación de estudios fraudulentos47.
Algunos ejemplos de fraude
Cada año, la Food and Drug Administration (FDA) inspecciona cientos de centros de ensayos clínicos y detecta desviaciones graves de las buenas prácticas. Clasifica el resultado de las inspecciones según su gravedad, siendo la «official action indicated» la más severa, que en 2013 representó el 2% de 644 inspecciones. Sin embargo, la falta de un mecanismo sistemático para difundir estos hallazgos hace que incluso irregularidades documentadas puedan pasar inadvertidas en la literatura científica. Una revisión realizada entre 1998 y 2013, encontró que 57 ensayos inspeccionados presentaban problemas importantes: falsificación (39%), mala notificación de eventos adversos (25%), violaciones de protocolo (74%), registros inexactos (61%) y fallos en la protección de los pacientes (53%), pero solo el 4% de los artículos que reportaban estos estudios mencionaron estos hechos, y ninguno fue corregido o retractado48.
Tres episodios que describimos a continuación ilustran cómo la falta de transparencia y la manipulación de datos pueden afectar a la salud pública.
El caso del rofecoxib mostró cómo la empresa que lo patentó promovió rofecoxib como un antinflamatorio no esteroideo (AINE) más seguro pese a señales tempranas de aumento del riesgo de eventos cardiovasculares. En el ensayo VIGOR, que comparaba rofecoxib con naproxeno, a pesar de que en los criterios de exclusión constaban los eventos cardiovasculares previos, se vio un incremento de los infartos de miocardio que se justificó por un efecto protector del naproxeno, que no se había descrito hasta el momento49. Pronto se supo que se omitieron eventos cardiovasculares en la publicación50. El ensayo APPROVe confirmó en 2004 un riesgo duplicado de eventos cardiovasculares, y metanálisis posteriores demostraron que la toxicidad cardiovascular era evidente desde el año 200051. Se estima que entre 89.000 y 139.000 estadounidenses sufrieron complicaciones cardiovasculares asociadas al rofecoxib, y hasta 88.000 infartos pudieron estar directamente relacionados con su uso, desencadenando demandas y multas millonarias50. El caso marcó un punto de inflexión en la vigilancia de seguridad y en la exigencia de transparencia en la investigación clínica.
Los ensayos RECORD evaluaron la eficacia y seguridad de rivaroxabán, un anticoagulante oral, en la prevención del tromboembolismo venoso (TEV) tras cirugía ortopédica mayor, en comparación con enoxaparina. El RECORD 4, un ensayo fase III en pacientes sometidos a artroplastia total de rodilla, mostró que rivaroxabán oral 10 mg una vez al día durante 10-14 días era superior a enoxaparina subcutánea 30 mg cada 12 horas en la prevención del TEV (6,9% vs. 10,1%; p = 0,01), con tasas de sangrado mayor aparentemente similares (0,7% vs. 0,3%; p = 0,11)52. Pronto se señalaron discrepancias llamativas entre las tasas de sangrado reportadas y las observadas en otros ensayos, atribuidas a redefiniciones de «sangrado mayor» y a escasa potencia estadística53. En 2011, la FDA consideró inaceptables ocho de los 16 centros inspeccionados y cuestionó la fiabilidad del ensayo debido a eliminación de registros, falsificación de datos y fallos en la aleatorización47. Aun así, durante años estos problemas no aparecieron en las publicaciones. En 2022, el presidente del comité del programa RECORD reconoció que la FDA no aceptó RECORD 4 como evidencia pivotal y que existían aleatorizaciones incorrectas y subregistro de eventos graves, aunque omitió que estas anomalías ya se conocían desde 2011 y no se hacía ninguna reflexión sobre el conflicto de interés que había en este retraso54.
Finalmente, el escándalo de valsartán evidenció cómo la manipulación de datos puede mantenerse oculta durante años. Entre 2002 y 2012, ensayos japoneses financiados indirectamente por la empresa fabricante informaron beneficios cardiovasculares del valsartán no atribuibles al control de la presión arterial55,56.
Investigaciones posteriores revelaron que empleados de dicha empresa participaron en el tratamiento de los datos sin declarar su conflicto de interés y manipularon los resultados para favorecer al fármaco. Esto condujo a retractaciones múltiples, dimisiones académicas y pérdida de confianza pública. Aunque un tribunal reconoció la manipulación intencionada de los datos, determinó que no había delito, pues la publicación científica no constituye «publicidad» según la legislación japonesa57.
Estos casos muestran cómo la integridad de los ensayos clínicos puede verse comprometida por fallos regulatorios, conflictos de intereses y manipulación activa de datos. También subrayan la necesidad de transparencia, acceso a datos individuales y vigilancia reforzada para proteger a los pacientes y garantizar la fiabilidad de la evidencia biomédica.
Las consecuencias del fraude
Las consecuencias del fraude científico son difíciles de mensurar. Cuando el fraude pasa inadvertido, la práctica clínica se sustenta sobre datos falsos y el perjuicio para el paciente es claro. Pero incluso cuando se descubre, su impacto puede persistir. Así lo muestra el estudio Delivery-I, que evaluó cómo los ensayos clínicos aleatorizados retractados afectan a las revisiones sistemáticas, metanálisis y guías clínicas. Se identificaron 1.330 ensayos clínicos aleatorizados (ECA) retractados hasta noviembre de 2024, y se buscaron 847 revisiones sistemáticas que los habían incluido en un total de 3.902 metanálisis. Al eliminar los estudios retractados, el 8,4% cambió la dirección del efecto, el 16% la significación estadística y el 3,9% ambas; en un 15,7% la magnitud del efecto varió más del 50%, sobre todo en metanálisis pequeños. Además, 68 revisiones afectadas habían sido utilizadas como base para 157 guías clínicas58. Estos hallazgos demuestran que la investigación fraudulenta erosiona de manera sustancial el ecosistema de la evidencia, alterando síntesis de investigación, recomendaciones clínicas y el conjunto de la práctica médica basada en la evidencia, impactando de manera inevitable en la confianza de los profesionales en los resultados compartidos por la comunidad científica.
Conclusiones
El proceso de toma de decisiones clínica es de por sí complejo y debería incorporar las preferencias del paciente, la experiencia clínica previa y la mejor evidencia disponible.
En este artículo hemos querido enfatizar que clínicos e investigadores en salud no debemos confiar de manera automática ni acrítica en conclusiones o recomendaciones derivadas de dicha investigación, sino considerarlas a la luz de problemas que dificultan la toma de decisiones basada en la evidencia, entre los que se incluyen los sesgos, los heurísticos y, de forma ocasional, el fraude, que pueden distorsionar la aplicación del conocimiento generado. Es fundamental comprender críticamente las suposiciones y retos subyacentes y preguntarnos desde la prudencia qué cambios supone el adoptar una nueva recomendación o tomar una decisión sin esta reflexión. Por último, queremos recordar la importancia de abogar por una ciencia basada en el rigor y la honestidad, y que desde la profesionalidad y la ética no permitamos que las actividades fraudulentas queden impunes o que sean rentables.
Consideraciones
Este artículo es una versión ampliada y revisada de una presentación en el XLV Congreso de la semFYC de Madrid 2025.
Conflicto de intereses
Ambos autores afirman no presentar conflicto de intereses con lo expresado en el presente trabajo.
